Architecture | Building Modular Systems with Redis

Introduction
Recent years saw growing popularity of modular approach to architecting software. Software systems move away from monolith codebases towards independently deployed and executed modules. In the article, we avoid calling these architectures “microservices” or using “Kubernetes” in every other sentence. Microservice-based architecture is just one of many ways to modularise software, while the challenges remain the same.
Modular architectures, while helping create large and resilient software, bring challenges absent in monolith software. Think of concerns such as sharing of data between modules, reacting to events, orchestrating work scenarios spanning over multiple services running on separate instances. While building StellaControl we tried many ways to address them. Redis turned out to be indispensable in these efforts.
This article is not another Redis “Hello World” tutorial. Instead, we demonstrate real-life architectural challenges encountered in our system and how Redis helped us resolve them. We presume reader’s familiarity with concepts such as cache, message bus etc. If you’d like to learn more about Redis before diving into the article, please check Redis Developer Hub for excellent documentation and sample code. For more Redis practices and recommendations we refer you to Redis Best Practices.
Enter StellaControl
Decades of technological progress in GSM technology made us expect uninterrupted flow of data into our mobile devices. We get irritated when this is not the case. Yet it happens a lot. Our company designs and builds heavy-duty devices amplifying GSM signals attenuated by construction materials, electrical equipment, unique terrain features, or distance. They work in thousands of offices, hospitals, hotels, residences, houses, ships, and drilling platforms all over the world.
Our fleet of devices, called iRepeaters, grows steadily and works diligently. But they don’t just boost the signal. They also send us in real time their vital parameters and network statistics. They listen to a variety of commands. With these commands, we can configure devices remotely. We can also send over-the-air software updates and patches. Welcome to StellaControl, the IoT monitoring platform for fleet of iRepeaters.
We won’t analyze here the entire architecture, which would likely require a series of articles. And it is impossible to tell in a few sentences of all the uses we found for Redis. As we discovered, it can be used in so many ways! Instead, we analyze few selected scenarios where we used Redis to address architectural challenges.
Before proceeding into details, lets have a quick look at StellaControl components to let you better understand the discussed scenarios.
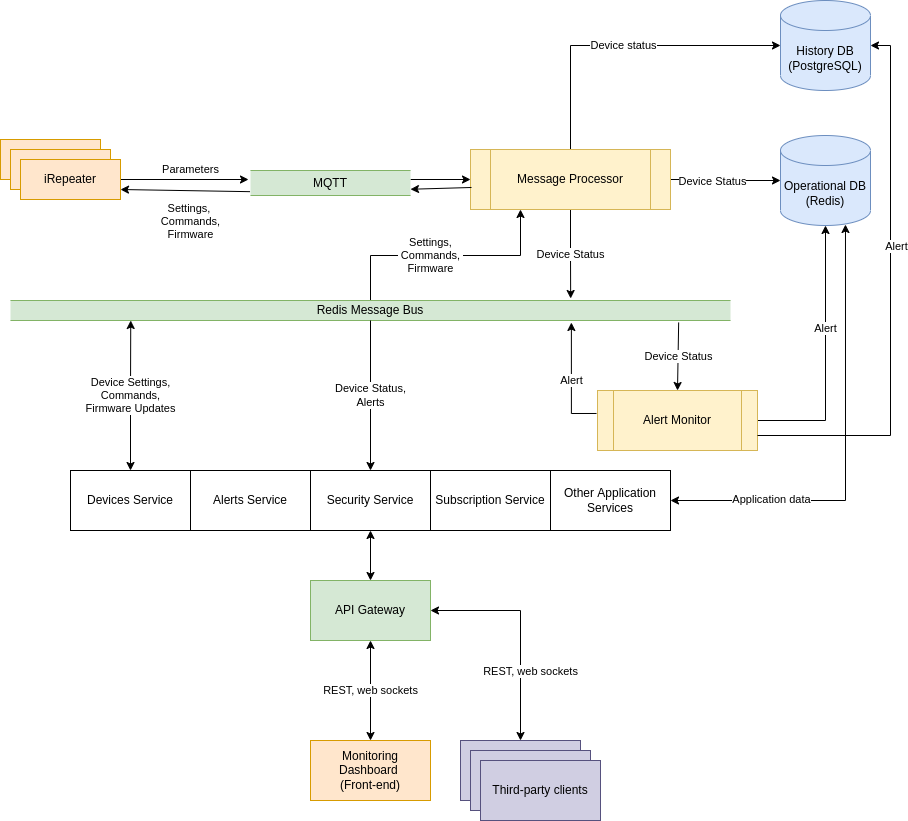
Processing of Incoming Device Messages
At the heart of the system is Message Processor. It is responsible for receiving vital parameters of devices via MQTT and storing them in the history database. In other direction, it’s responsible for delivering settings, commands and firmware updates from clients such as Monitoring Dashboard or third-party systems back to devices.
All other parts of the system need to know about the current status of devices, in real-time. For example, Alert Monitor analyzes the vital parameters of each device. If any problems are detected, it will promptly notify device users and system administrators.
Using MQTT, devices regularly report to the platform their vital parameters. It typically happens once every 10 minutes, but sometimes more frequently. At times, even once per second, when an administrator configures or troubleshoots a device and needs to see how it reacts in real time. This can result in message flow of thousands messages per minute.
Legacy Solution with SQL Database
In the previous version of the system Message Processor stored the received device status in the SQL database. All other services were polling this database periodically, using the REST endpoint to obtain the most recent status. With few hundred devices this worked sufficiently well.
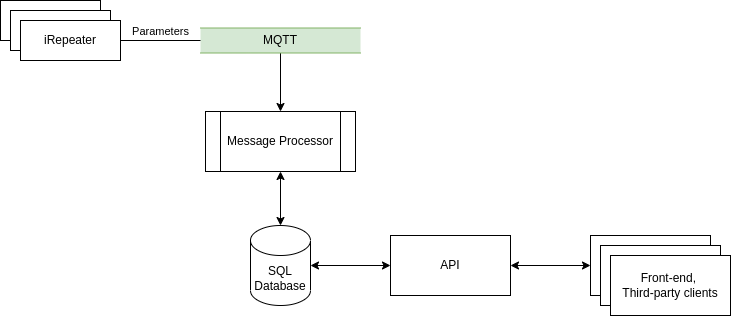
Once we went into thousands, serious problems appeared. Thousands of messages per minute result in tens of thousands of SQL writes, accompanied by cascade of index updates. At the same time, SQL reads come in from services and interactive users watching devices live. SQL writes easily outcompete SQL reads. This leads to increasingly slow queries. Large number of queries competing with writes cause transaction deadlocks. This leads to congestion of incoming traffic and occasional data loss. Message Processor was increasingly unable to cope with sudden bursts of device activity.
Efficient Solution with Redis Cache and Redis Message Bus
The above is a schoolbook problem of any real-time message processing architecture. To allow scaling and avoid performance problems, we had to decouple data ingestion from data consumption. This is where Redis comes in picture.
Redis is a two-sided coin, offering two distinct modes of functionality:
- Cache: efficient in-memory database with persistence
- Message Bus: pub/sub message dispatcher
Both functionalities were required to efficiently solve the challenge of decoupling message ingestion from message consumption, both competing for the same scarce resources. We came up with the following architecture:

In it, we see:
- Decoupling of message reception from message ingestion, with small Redis instance serving as FIFO queue.
- Polling of device status is replaced by subscriptions to Redis message queue
- Front-end and third-party clients query the data from fast Redis cache
- Front-end and third-party clients subscribe to high frequency status updates through web-sockets
Redis used as a fast FIFO queue for storing the incoming binary messages
As first, Message Receiver accepts device status updates and stores them as-is in dedicated Redis database serving as FIFO queue. Binary data is serialized to Base64 and stored with SET command under key containing device serial number and timestamp, for example sc:message:HN88192AD:1661758645273. The key has expiration time of one day. If the status is not processed within one day, it will be discarded.
On the other side, there’s the Message Processor. It picks and processes batches of queued messages at its own speed. Even if there are bursts of activity of devices, the Message Processor will not be impacted. There will be a brief build-up of unprocessed messages in the queue, but in time this will be resolved. If our fleet keeps growing, we will simply add more instances of Message Processors to handle the load.
Redis used as a persistent store of recent device status
The received data isn’t directly usable. For maximal efficiency and minimal data costs, devices use the protobuf protocol to encode the data as tightly as possible. Message processor unpacks these concise messages, analyzes the data, and converts them to JSON format, easy to interpret by other services. We can now store the status of each device permanently in operational database using keys containing device serial number, for example sc:status:HN88192AD.
Native JSON data type is available in Redis Enterprise Cloud and would come in handy here. Currently, we serialize JSON messages to strings. RedisJSON has many other benefits, such as read/write access to sub-elements without retrieving and parsing entire messages.
Redis used as message bus to notify other parts of the system about new arrivals
Parsed and stored device status can now be retrieved from Redis store using the REST endpoint. Yet, although getting data from Redis cache is way faster than from SQL database, this isn’t used much. Polling means unwanted delays in services reacting to status changes. It also means unnecessary pressure on the system while there is no traffic from devices incoming. There’s a better way available.
Message Processor announces new status using Redis message bus on sc:device-status topic. Other services can subscribe to these notifications. They will now instantly receive device status as it comes in. And they can act upon it instantly, without delays caused by polling. For example:
-
Alert Monitor analyses device status and triggers alerts if vital parameters are outside the allowed ranges.
-
Application Service broadcasts device status to UI clients via web sockets. Device status displayed on monitoring dashboards is always up to date.
-
Third Party Integration Service sends device status to webhooks provided by system integrators. They are no longer free to DDOS our back-end by polling for the status updates.
All this ensures smooth and instant processing of the incoming traffic. If traffic is low and stable, services remain idle. If traffic goes up, the services pick up but stay within predictable bounds defined by the queue processing speed. In any case, the pressure caused by periodic polling for the status of devices which maybe don’t communicate at all, is entirely gone.
Alert Throttling
Alert Monitor, already mentioned above, is responsible for analyzing the received vital parameters of devices. If any of these parameters is outside the allowed ranges, an alert must be triggered. A good example is device temperature which must not exceed a certain value. If the internal fan fails or air vents are accidentally blocked, the temperature goes up which can eventually destroy the circuits. Therefore we must notify the device owner and our operators quickly.
This brings the challenge of alert throttling. If overheating device communicates once per seconds, we shouldn’t trigger an alert every second. If conditions persist, once per hour is enough.
We found out that Redis cache key expiration is a perfect mechanism for time-based throttling.
The mechanism is very simple:
- When alert is detected, it is stored in Redis cache as record expiring in one hour.
- When device triggers another temperature alert, Alert Monitor checks if an identical entry already exists in the cache.
- If alert already exists, the new one is discarded.
- After one hour, the first detected alert expires, and Redis removes it from cache.
- If another temperature alert is detected now, it will be treated as legitimate new alert.
Alert Notifications
Detection of alerts is just the first step. Other parts of the system want to know about it, for example:
- Notification Service, which sends emails and SMS messages to administrators
- Application Service Alert needs to broadcast the alert to UI clients via web sockets
In the previous version of the system, we stored alerts in the SQL database. Services and applications used polling to detect new alerts. For the same reasons as with device status, this was inefficient. We now use Redis message bus to do it better.
Redis message bus is used to broadcast device alerts to other parts of the system
Sending out notifications brings the same challenge of throttling. Critical alerts aside, users don’t want to be troubled with emails and SMS messages every minute. They want to receive bundled notifications once every few hours. To do this, we again used Redis cache.
Redis cache is used to accumulate notifications for each user
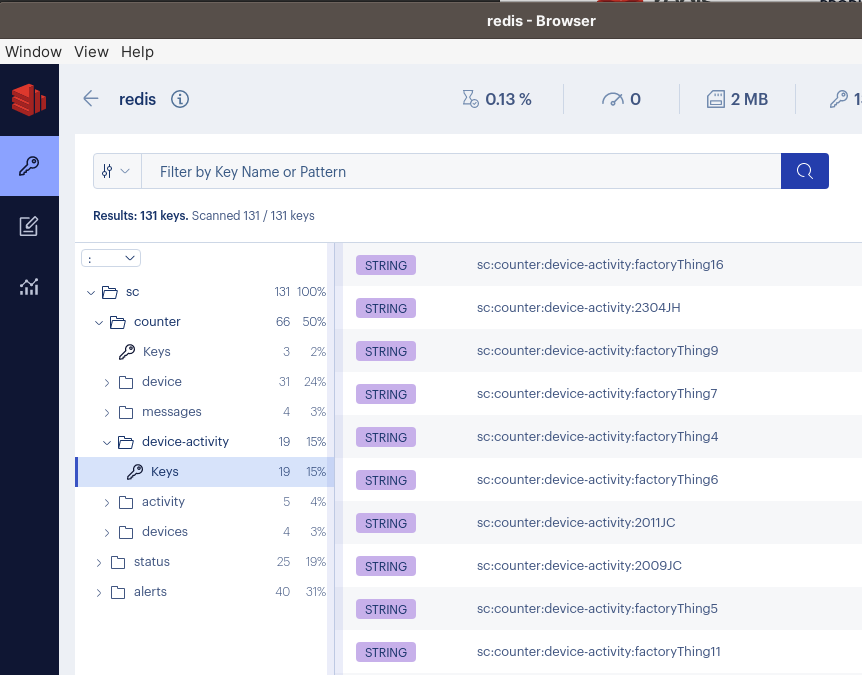
When alert notification service receives alert on message bus, it stores the alert in cache. It uses key prefix to bundle alert notifications per user, for example sc:alerts:<userId>:<notificationId>. The prefix is very useful. The periodically running process for delivering notifications uses it to discover entire batch of notifications for each user. For example, Redis KEYS sc:alerts:112233:* will return all keys representing pending alert notifications of user 112233. Fetched notifications are sent to user in one batch and removed from Redis cache.
Notice how we use namespaces when storing data in Redis. Our keys contain words separated with : character. It brings structure to your data and helps avoid key conflicts. It also helps see the data as a hierarchy in RedisInsight Desktop GUI, a tool for interacting with Redis data store:
Third-Party API Throttling
Third-Party API is offered to large customers and system integrators. It allows them to tap directly into their data and integrate it with their monitoring dashboards and alerting solutions. Access to any endpoint available to the outside world must be throttled, to prevent deliberate or accidental denial-of-service incidents.
With Redis and expiring cache keys, we implemented API throttling quickly. Assume that we allow users to perform 1000 calls per hour. If they exceed the hourly limit, subsequent calls should end with the HTTP 429 Too Many Requests error. We came up with the following implementation:
- Between the actual API endpoint and the third-party client there’s a little proxy server with access to the Redis instance.
- When an API call comes in, we identify and authorize the customer using request headers.
- We store API call counter for each customer under
sc:api:<customerid>:callskey usingINCRBYcommand. The command sets the counter to1if it doesn’t exist yet. Otherwise it increases the counter for the customer. Finally, it returns the new value of the counter. - If this is the first call within the hour, the command will return
1. In this case, we useEXPIREcommand to set the expiration time of the key to3600seconds. - If this is a subsequent call, the command will return the total count of calls so far.
- If the count exceeds
1000, we returnHTTP 429to the client - Eventually, the hour passes, the counter expires and Redis removes it. The customer performs another call, which starts counting from
1again.
A similar mechanism can be easily used to implement any kind of throttling within the system.
Thoughts on How to Use Redis
Use Redis By Default
Because Redis can play so many roles efficiently, it’s good to adapt “Redis first” approach. Any time there’s a need for services communicating with each other or sharing some data, we choose Redis as a standard way to go. Even if such concerns arise within the same process, we still choose Redis. This approach pays off, as it makes it easy way to refactor the system and break growing services into smaller parts when needed.
Make it Easy for Developers
The key to efficient Redis usage was making it ubiquitous from the developer’s perspective. With Redis as the default solution for data caching and communication, we created simple Redis wrappers for the developer’s use. They address such concerns as configuration discovery, error handling, logging, connectivity issues, etc. These must be implemented consistently across the code base. A developer using Redis should only focus on the actual task at hand. See below a few examples of Redis wrappers in action:
// Retrieve cached device status
await useCache(async cache => {
const status = await cache.get(`sc:status:${serialNumber}`)
if (status) {
...
}
})
// Subscribe to alert notifications
await subscribeMessage({
type: MessageType.Alert,
handler: async (message) => {
const { device, alert } = message
...
}
})
// Submit a message to message bus
const message = createMessage(MessageType.DeviceActivated, { serialNumber })
await publishMessage({ message })
With these wrappers, it’s trivially easy for a developer to use Redis. All tasks important for the resilience and stability of the system, such as logging and error handling, are taken care of internally. Developers can now focus on their primary tasks.
Deployment and the Future
As of now, we use several self-hosted Redis instances, efficiently serving our current needs. We’re currently exploring additional possibilities available with Redis Enterprise, which might help us grow the system further:
-
RedisGears, which is Redis answer to serverless architectures. It allows building data processing flows using functions deployed along with the database. Our current application architecture involves a substantial amount of daemon services whose primary task is to watch data streams and react to them. This is precisely what RedisGears functions do. We think that RedisGears would help us reduce the complexity and cost of system deployment, because fewer server instances would be required.
-
RediSearch combined with RedisJSON, free-text indexing and search engine for the entirety of data collected in the system. The list of possible uses of such an engine is endless. Currently, we do searches by querying the SQL database. SQL is rigid and requires a lot of tedious data mapping code. We expect that RediSearch could substantially cut the amount of code involved in data searches.
All these are readily available on Redis Enterprise Cloud.
Summary
In the end, Redis came to be an indispensable component in our system. It is currently a glue connecting all vital parts of the platform, providing efficient communication and super-fast data store with magic abilities such as data expiration.
Redis did not eliminate more traditional components. For example, we still use PostgreSQL database as preferred long-term data store for terabytes of historical data of devices, reaching back years, useful for statistics and troubleshooting. But we no longer use it as source of truth about what’s happening now, at this very moment. Such queries must be answered instantly and frequently. They’re best handled with fast in-memory data store and message bus, all provided by Redis. We adapted the approach of using the best tool for the task at hand. Redis excels in many of these tasks, where performance and resilience are crucial.
References
This article is in collaboration with Redis.
Learn more: